
Transformers
Statutory warning: You will need lot of attention to go through the details, so get ready. 🏋
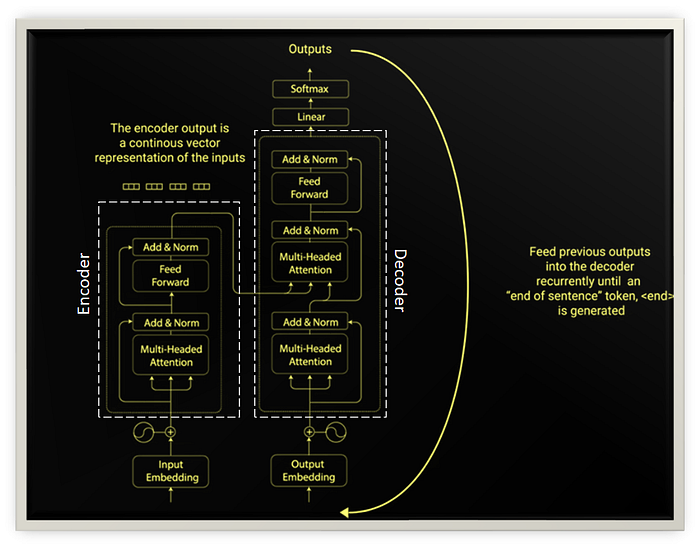
Below is the Transformer image seen across blog posts explaining Transformers and is provided in original “Attention is all you need” paper as well. It was intimidating for me in the beginning & I am sure it would be for you too but do not worry, as we decipher the mystery you will begin to enjoy it.
So what are Transformers & why are they more used in conjunction with attention mechanism?
The Transformer in NLP is a novel architecture that aims to solve sequence-to-sequence tasks while handling long-range dependencies with ease. The Transformer was proposed in the paper Attention Is All You Need. It is recommended reading for anyone interested in NLP.
Quoting from the paper:
“The Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution.”
Here, “transduction” means the conversion of input sequences into output sequences. The idea behind Transformer is to handle the dependencies between input and output with attention and recurrence completely.
Attention mechanism
Attention mechanism was actually proposed by Bahdanau et al in the paper titled “Neural Machine Translation by Jointly Learning to Align and Translate” in the year 2015. Prior to this, neural machine translation was based on encoder-decoder RNNs/LSTMs. But was faced with issue of long-range dependency problem of RNN/LSTMs as well as another problem is that there is no way to give more importance to some of the input words compared to others while translating the sentence. The attention mechanism emerged as an improvement in this aspect over the encoder decoder-based neural machine translation system in natural language processing (NLP). Attention mechanism has an infinte reference window unlike RNNs, LSTMs which have a shorter reference window so when sentence gets longer, RNNs cannot access word generated earlier in the sequence.
“Bahdanau et al (2015) came up with a simple but elegant idea where they suggested that not only can all the input words be taken into account in the context vector, but relative importance should also be given to each one of them.”
So, whenever the proposed model generates a sentence, it searches for a set of positions in the encoder hidden states where the most relevant information is available. This idea is called ‘Attention’.
For more on attention in Seq2Seq (encoder decoder) models, read this blog from Jalammar:
So don’t carried away by the title of the paper “Attention Is All You Need” 2017 but they build on top (Self Attention, Multi head Attention) this pre existing attention mechanism with Transformer architecture to produce better results. We will cover self attention, multi head attention further in detail further in this blog.
Understanding Transformers
Transformers are taking the NLP world by storm. Transformers have replaced traditional RNNs, LSTMs, GRUs etc. and to name few transformers are BERT, GPT-2, GPT-3 etc. They are currently being used in many applications like Machine Language Translation (MLT),Conversational chatbots, text generation, text summarization etc.
How do they work?
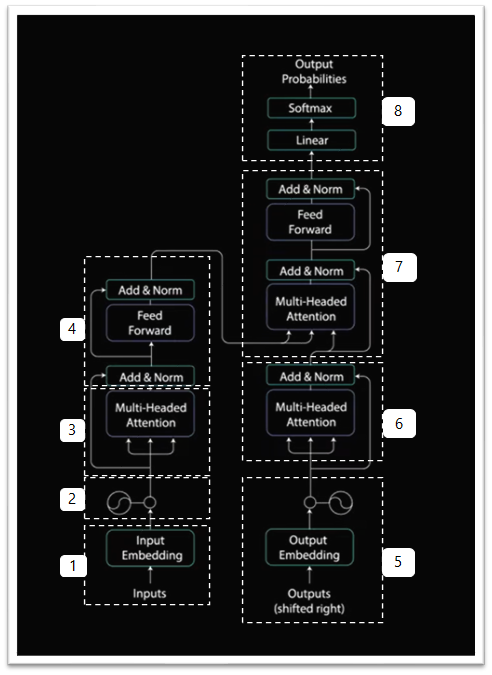
Transformers are attention based encoder decoder type architecture. Just that the encoder decoder are not recurrent neural networks based. We will discuss this in this detail further. On the high level the encoder maps the input sequence into an abstract continuous representation that holds all the learned information of that input. Decoder then takes that continuous representation and step by step generates a single output while also being fed to previous output.
Lets take an example for better understanding.
We would consider conversational chatbot which takes “Hi, How are you?” as input and outputs “I am fine”.

Lets break the mechanics of the network step by step.
Transformer Encoder
Step 1: Feeding our input to word Embedding layer.
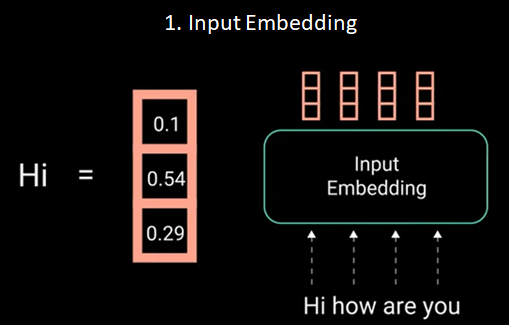
A word embedding layer can be thought of as a look up table to grab a learned vector of representation of each word. Neural networks learn through numbers so each word maps to a vector with continuous values to represent that word.
Step 2: Inject Positional Information into the embeddings
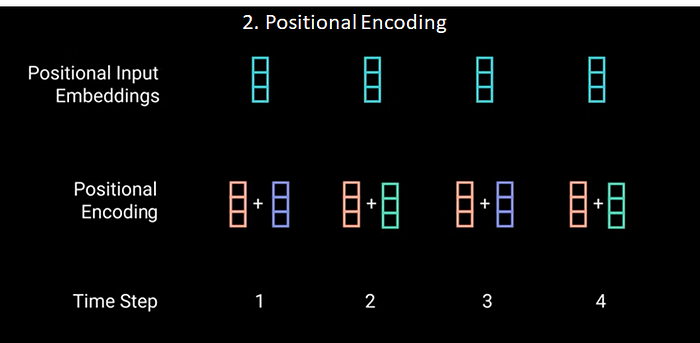
Transformer encoder has no recurrence like recurrent neural networks. We must add information about the positions into the input embeddings. This is done using the positional encoding. These positional encoding vector are added to their corresponding input embedding vector. This successfully gives the network information on the position of each vector
Step 3: Encoder Layer
Encoder Layers job is to map all input sequence into an abstract continuous representation that holds the learned information for that entire sequence. It contains 2 sub modules Multi-headed Attention followed by fully connected network. There are also residual connections around each of the 2 sub modules followed by a layer normalization.
Multi-headed Attention module
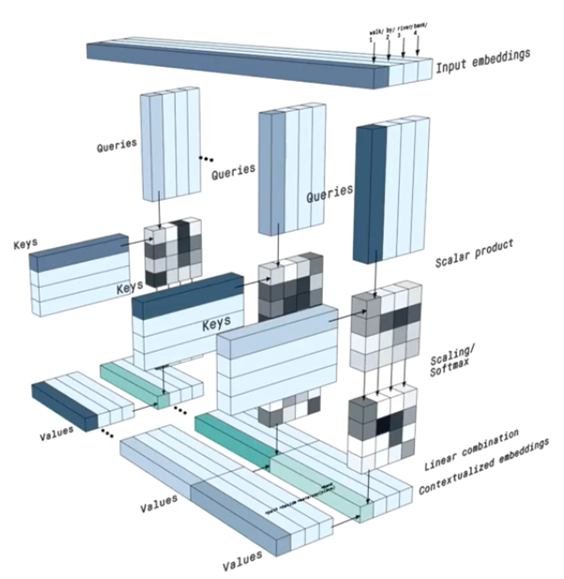
Multi headed attention in the encoder applies a specific attention mechanism called Self Attention. It allows a model to associate each individual word in the input to other words in the input. So in our example its possible that our model learns to associate the word “you” with “how are” and its also possible that model learns the word structure in this pattern are typically question so respond appropriately.
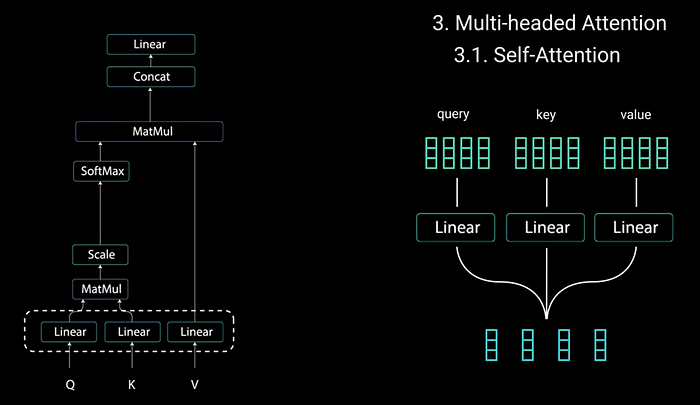
In order to achieve attention we feed the input into 3 distinct fully connected(FC) layers to create the “Query”, “Key” & “Value” vectors.
A good explanation for this can be found over stackexchange stating.:
“The key/value/query concepts come from retrieval systems. For example, when you type a query to search for some video on Youtube, the search engine will map your query against a set of keys (video title, description etc.) associated with candidate videos in the database, then present you the best matched videos (values).”
So how is this related to self attention?
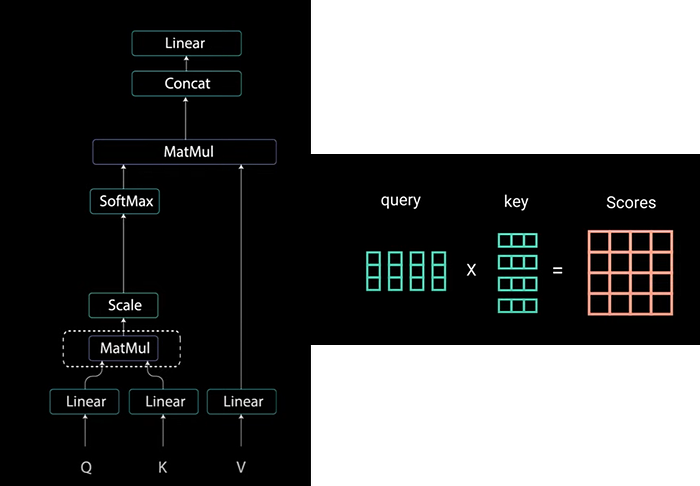
Queries & Keys undergoes a dot product matrix multiplication to produce a score matrix.

The score matrix determines how much focus should a word be put on other words. So each word will have a score to correspond to other words in the time step. The higher the score the more the focus. This is how queries are mapped to keys.
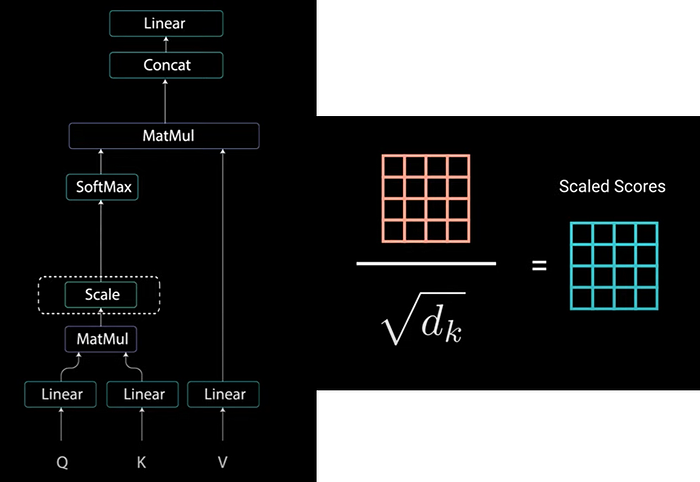
Then the score get scaled down by getting divided by the square root of the dimension of the queries & the keys. This is to allow for more stable gradients as multiplying values can have exploding effects.
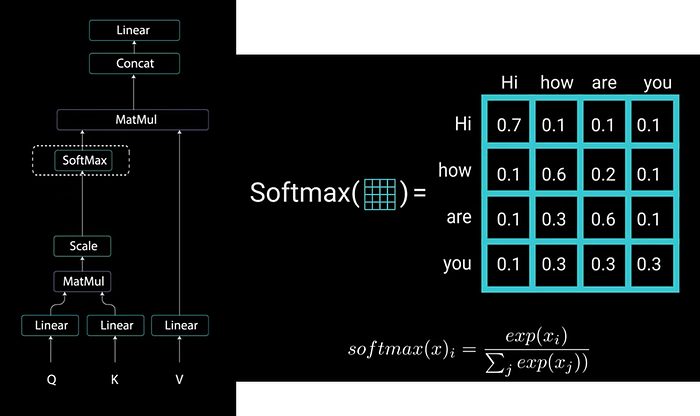
Next we take softmax of the scaled scores to get attention weights which gives you the probability values between 0 & 1. By doing softmax the higher scores get heightened and the lower scores are depressed. This allows the model be more confident on which words to attend to.
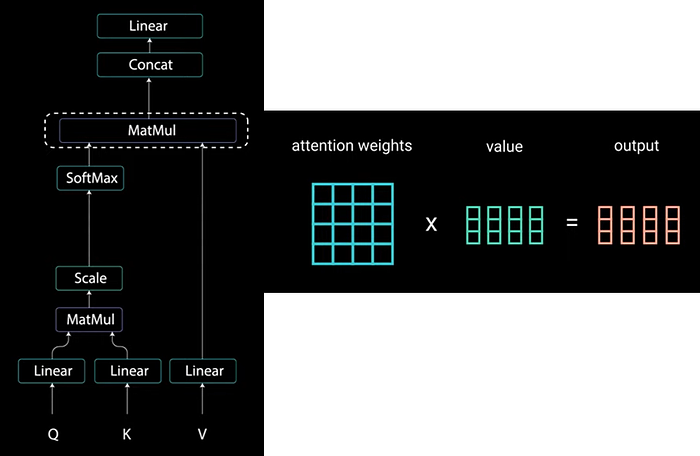
Then we take the attention weights and multiply by the value vector to get an output vector. The higher softmax scores will keep the value of the words the model learn is more important & the lower scores will drown out the irrelevant words.
Finally we feed the output vector into linear layer to process.

To make this is a multi-headed attention computation you need to split the query, key & value into n vectors before applying self attention. The split vectors then go through the same self attention process individually. Each self attention process is called a head.
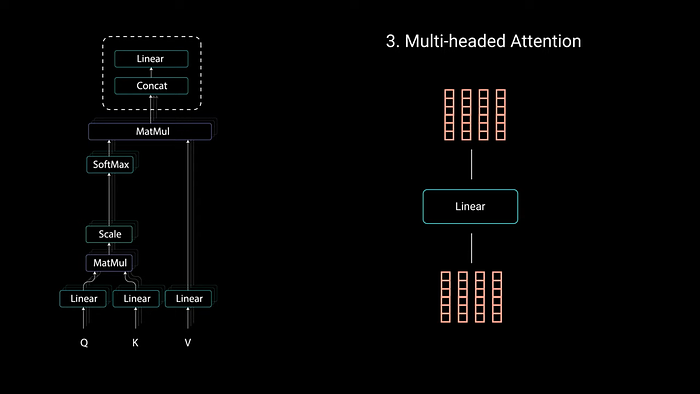
Each head produces an output vector that gets concatenated into a single vector before going through the final linear layer. In theory each head would learn something different therefore giving encoder model more representation power.
To sum it up, multi headed attention is a module in a transformer network that computes the attention weights for the input and produces an output vector with encoded information on how each word should attend to all other words in a sequence.
Step 4: Residual Connection, Layer Normalization & Pointwise Feed Forward
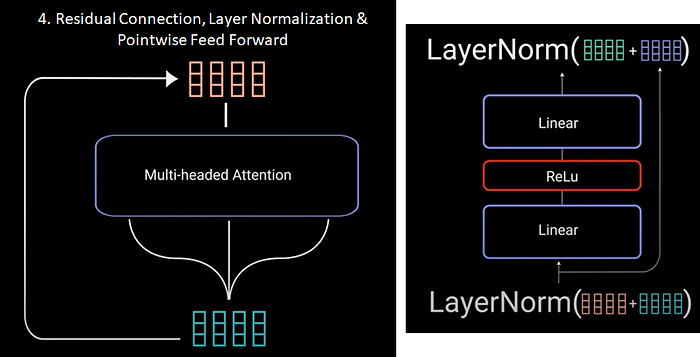
Next step the multi headed output vector is added to the original input. This is called a residual connection. The output of residual connection goes through a layer normalization. The normalized residual output gets fed into a pointwise feed forward network for further processing. The feed forward network is a couple of linear layers with a Relu activation in between. The output of that is again added to the input of the point wise feed forward network and further normalized. The residual connections helps the network train by allowing gradients to flow through the network directly. The layer normalizations are used to stabilize the network which results in substantially reducing the training time necessary and the feed forward network are used to further process the attention output giving it a richer representation.
Finally encoder part is done. The output with attention information from encoder will help decoder focus on the appropriate words in the input during the decoding process.
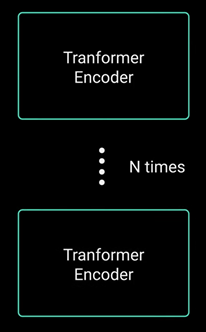
You can stack the encoder “N” times to further encode the information where each layer has the opportunity to learn different attention representations therefore potentially boosting the predictive power of transformer network.
Transformer Decoder
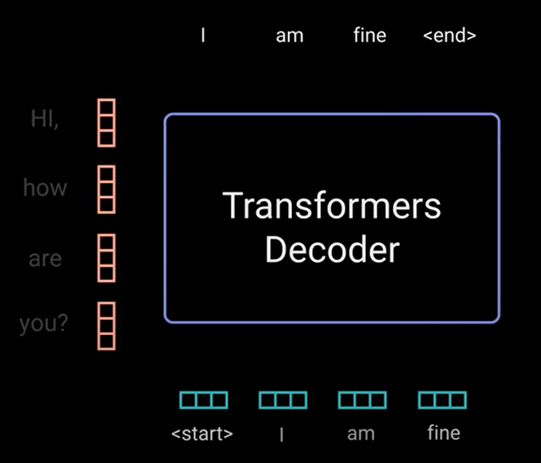
The decoder job is to generate text sequences. The decoder has similar sub layers as the encoder. It has 2 multi headed attention layers, a pointwise feed forward layer with residual connections and layer normalization after each sub layer. These sub layers behave similarly to layers in the encoder but each multi headed attention layer has a different job. Its capped off with a linear layer that acts like a classifier and the softmax to get word probabilities. The decoder are auto regressive, it takes in the list of previous outputs as inputs as well as the encoder outputs that contains the attention information from the input. The decoder stops decoding when it generates an end token as an output. Lets walk through the decoding steps.
Step 5: Output Embedding & Positional Encoding
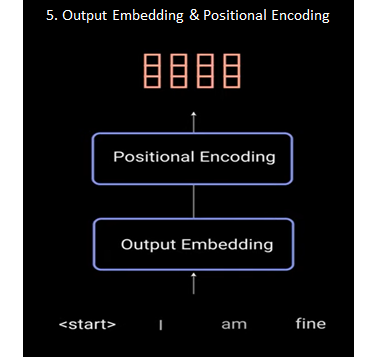
The input goes through an embedding layer and a positional encoding layer to get positional embeddings.
Step 6: Decoder Multi-Headed Attention 1
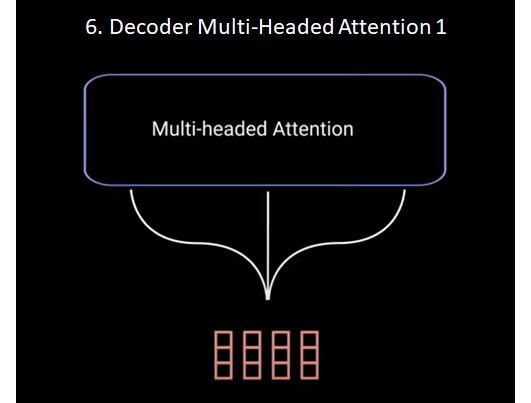
The positional embeddings gets fed into the first multi headed attention layer which computes the attention score for the decoders input. This multi headed attention layer operates slightly different. Since decoders are auto regressive and generates the sequence word by word you need to prevent it from condition into future tokens.
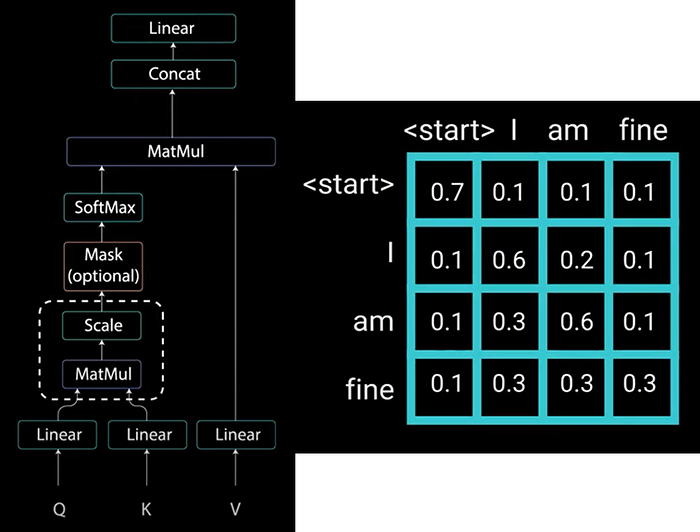
For example when computing attention scores on the word “am” you should have not access to the word “fine” because that word is a future word that was generated after. The word “am” should have access to itself and the words before. This is true for all the other words where they can only attend to previous words. We need a method to prevent computing attention scores for future words. This method is called masking. In order to prevent the decoder from looking at future tokens you need to apply a look ahead mask. The mask is added before calculating the softmax and after scaling the scores.
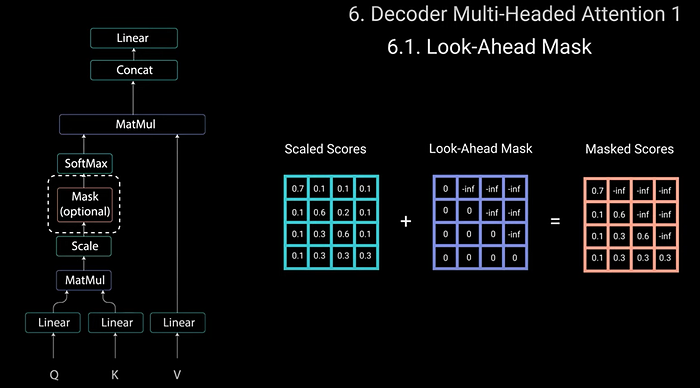
The mask is a matrix thats the same size as the attention scores filled with values of materials and negative infinity. When you add the mask to the scaled attention you get a matrix of scores with the top right triangle filled with negative infinity.
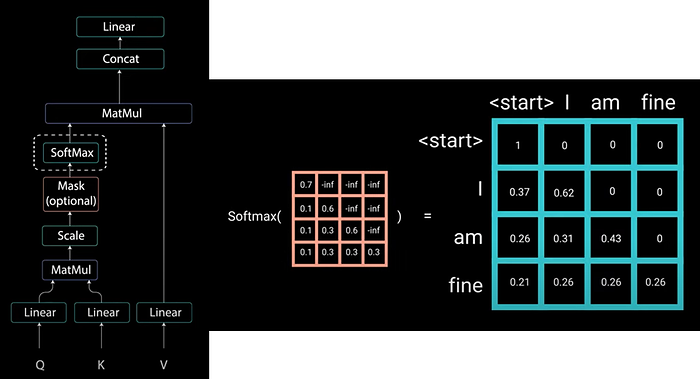
The reason for this is when you take softmax of the mask scores the negative infinity get zeroed out leaving a zero attention score for a future tokens. As you can seen the scores for “am” have values for itself and all other words before it but zero for the word “fine”. This tells model to put no focus on those words. This masking is the only difference on how the attention scores are calculated in the first multi headed attention layer.
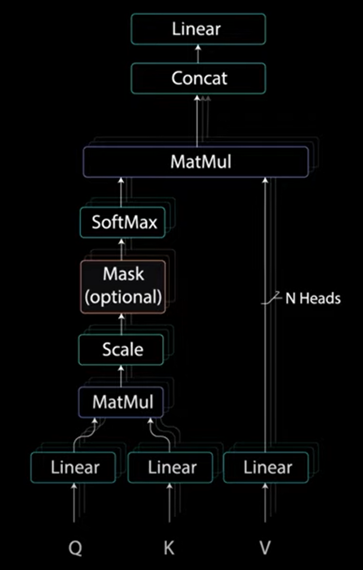
These layers have multiple heads that the mask being applied to before getting concatenated and fed through a linear layer for further processing. The output of first multi headed attention is a mask output vector with information on how the model should attend on the decoders inputs.
Step 7: Decoder Multi-Headed Attention 2
Now onto the second multi headed attention layer. For this layer the encoders output are the queries & keys where as the first multi headed attention layer outputs are the values. This process matches the encoders input to decoders input allowing the decoder to decide which encoder input is relevant to put focus on. The output of second multi headed attention goes through a point wise feed forward layer for further processing.
Step 8: Linear Classifier
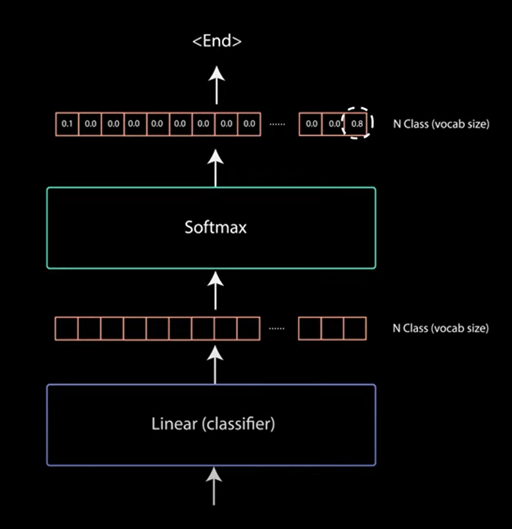
The output of final point wise feed forward layer goes through a final linear layer that access a classifier. The classifier is as big as the number of classes you have. For example if you have 10k classes for 10k words then the output of that classifier will be of size 10k. The output of classifier gets fed to softmax layer. The softmax layer produces probability scores between 0 & 1 for each class. We take index of the highest probability score and that equals our predicted word. The decoder then takes the output and adds it to the list of decoder inputs and continue to decode again until end token is predicted. For our case the highest probability prediction is the final class which is assigned to the end token. This is how the decoder generates the output.
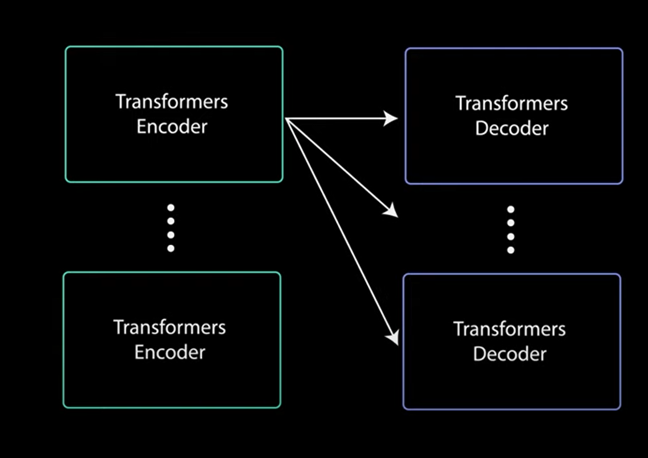
The decoder can be stacked n layers high. Each layer taking in inputs from the encoder and the layers before it. By stacking layers the model can learn to extract and focus on different combinations of attention from its attention heads potentially boosting its predictive power.
So that's Transformers for you Ladies & Gentlemen.
Will be updating above steps with Pytorch code soon, so stay tuned and keep clapping 👏🏻
References:
1. The A.I. Hacker - Michael Phi:https://www.youtube.com/watch?v=4Bdc55j80l8&feature=emb_logo
2. Peltarion- https://www.youtube.com/watch?time_continue=539&v=-9vVhYEXeyQ&feature=emb_logo
3. https://www.analyticsvidhya.com/blog/2019/06/understanding-transformers-nlp-state-of-the-art-models/
4. https://www.analyticsvidhya.com/blog/2019/11/comprehensive-guide-attention-mechanism-deep-learning/